Introducción a Gatling
En la entrada de hoy, vamos a hablar de Gatling, una herramienta de la que me habían hablado hace tiempo y que tenía muchas ganas de probar.
Introducción
Gatling es una herramienta para hacer pruebas de cargas sobre aplicaciones, y que está diseñada para DevOps e integración continua. Gatling ofrece diferentes modos de uso, por un lado, tenemos la posibilidad de ejecutar un bundle, del que hablaremos después y, por otro lado, tenemos la posibilidad de crear un proyecto y escribir ahí nuestros escenarios de prueba, que será por donde vamos a empezar en esta entrada.
Antes de comenzar, decir que para utilizar Gatling necesitaremos tener instalado Java (versiones 8 y 11 son soportadas), Scala (para Gatling 3.5, la versión actual en el momento en el que se escribe este post, requiere Scala 2.13) y, finalmente, descargar Gatling o, bien, si vamos a crear un proyecto, apuntar a la versión correspondiente de la dependencia a la librería de Gatling. Más información aquí.
Proyecto local
Como hemos comentado, vamos a empezar usando Gatling mediante la creación de un proyecto en local, que posteriormente ejecutaremos sobre la aplicación que queremos probar.
Existen varias alternativas para comenzar, la primera es usar un arquetipo que proporcionan la gente de Gatling o, bien, clonar un proyecto de demostración disponible en Github.
Nosotros vamos a partir de un proyecto existente, disponible aquí, y vamos a explicar paso por paso cada parte.
Comenzando por la estructura de proyecto, tenemos lo siguiente:
.
├── README.md
├── docker-compose.yml
├── pom.xml
└── src/Tenemos, por tanto, un proyecto Maven clásico y, adicionalmente, un fichero docker-compose.yml con la aplicación que queremos probar. Respecto a la carpeta src donde vamos a tener el código relativo a la simluación (o simulaciones), tenemos lo siguiente:
src/
└── test/
├── resources/
│ ├── application.properties
│ ├── bodies/
│ ├── feeders/
│ ├── gatling.conf
│ └── logback-test.xml
└── scala/
├── Engine.scala
├── IDEPathHelper.scala
├── Recorder.scala
└── com/En resources, tenemos los ficheros de configuración y algunos directorios donde vamos a poner ficheros que nos harán falta, como por ejemplo, los ficheros JSON de los cuerpos de nuestras peticiones, o los ficheros CSV con los datos a utilizar (carpetas bodies y feeders, respectivamente). Después, voleremos sobre esto. Y, en la carpeta Scala, vamos a poner nuestro código con la simulación, concretamente en la carpeta com, es decir, la paquetería que decidamos utilizar (en mi caso, com.serrodcal).
Simulación
Ahora, es el turno de hablar de la simulación. La aplicación que queremos probar, disponible en el fichero docker-compose.yml, consiste en una aplicación Quarkus que expone un API REST de frutas, dicha aplicación se conecta a una base de datos Postgres donde almacena la información. La aplicación es totalmente reactiva, incluido el driver de la base de datos.
Nuestra simulación tendrá el siguiente flujo: crear una nueva fruta, consultar que se ha creado dicha fruta y, finalmente, la eliminamos de la base de datos:
.
├── ...
└── com/
└── serrodcal/
├── FruitSimulation.scala
├── LoadTestConfiguration.scala
└── requests/
├── CreateFruit.scala
├── DeleteFruit.scala
└── GetFruit.scalaEn este caso, hemos decidido separar las peticiones en una paquetería específica, así como, en ficheros separados (esto es opcional). Comencemos por la creación de una nueva fruta:
package com.serrodcal.requests
// Use ...Predef._ to get the implicit
import io.gatling.core.Predef._
import io.gatling.http.Predef._
object CreateFruit {
val feeder = csv("feeders/fruits.csv").circular
val headers = Map(
"Content-Type" -> "application/json",
)
val request = feed(feeder)
.exec(http("createFruit")
.post("/fruits/")
.headers(headers)
.body(ElFileBody("bodies/createFruit.json")).asJson
.check(status.is(201))
//.check(header("SOME-HEADER").saveAs("whatever"))
.check(jsonPath("$.id").exists.saveAs("fruitId"))
)
}Tenemos un fichero CSV en la carpeta resources/feeders que contiene lo siguiente:
name
melon
strawberry
papayaLa primera línea, hace referencia al nombre de la columna y, justo debajo, los valores que vamos a utilizar en nuestra prueba. Si nos fijamos en el código, vemos que tenemos circular a la hora de indicar nuestro fichero CSV. Esto, es una de las estrategias que tenemos disponibles, que en este caso vamos a iterar de manera circular por los valores del fichero CSV.
Lo siguiente que vemos es la definición de un mapa que tendrá nuestras cabeceras HTTP. En este caso, simplemente indicando el Content-Type es suficiente.
Y, finalmente, definimos nuestra petición. Para ello, partimos del feed (del CSV) y por cada valor, vamos a lanzar una petición POST con el payload que tenemos en nuestra carpeta resources/bodies, comprobaremos que el código de respuesta es 201, que en el JSON que obtenemos de vuelta existe un campo id y, finalmente, guardamos ese identificador en la sesión de la prueba.
Respecto al cuerpo del mensaje, en la carpeta resources/bodies tenemos el siguiente template:
{
"name" : "${name}"
}Gatling va a sustituir la variable name por cada uno de los valores de los que se alimenta en el feed, es decir, los valores que tenemos en el CSV que mencionamos anteriormente.
La siguiente petición, se define de la siguiente manera:
package com.serrodcal.requests// Use ...Predef._ to get the implicit
import io.gatling.core.Predef._
import io.gatling.http.Predef._
object GetFruit {
val request = exec( session => session.set("id", session("fruitId").as[String]))
.exec(http("getFruits")
.get("/fruits/${id}")
.check(status.is(200))
.check(jsonPath("$.id").exists)
.check(jsonPath("$.name").exists)
)
}
Es bastante similar a la anterior, salvo que aquí recogemos la variable que almacenamos en la petición anterior que contiene el identificador de la nueva fruta que hemos creado, y la renombramos como id. Con ello, sólo tenemos que indicar en la URI de nuestra petición ${id}. Finalmente, comprobamos que obtenemos como código de respuesta un 200, así como, que existen los campos id y name en el cuerpo de la respuesta.
La ultima petición no la vamos a comentar para no hacer muy largo el post, está disponible aquí y sigue la misma lógica que hasta ahora. Simplemente, comentar que podemos complicar la lógica de las peticiones y las comprobaciones tanto como se quiera, ya que, Gatling proporciona muchas funciones para ello.
Finalmente, tenemos dos clases más, FruitSimulation y LocalTestConfiguration. Empezando por la segunda, tenemos simplemente la carga de la base de nuestra URL a partir de un fichero de configuración llamado application.properties en resources:
package com.serrodcal
import com.typesafe.config.ConfigFactory
object LoadTestConfiguration {
val conf = ConfigFactory.load()
val baseUrl = conf.getString("baseUrl")
}La simulación tiene el siguiente aspecto:
package com.serrodcal
import com.serrodcal.requests.{CreateFruit, DeleteFruit, GetFruit}
import io.gatling.core.Predef._
import io.gatling.http.Predef._
import scala.concurrent.duration._
class FruitSimulation extends Simulation {
val httpProtocol = http
.baseUrl(LoadTestConfiguration.baseUrl)
val scn = scenario("FruitSimulation")
.exec(CreateFruit.request, GetFruit.request, DeleteFruit.request)
setUp(
scn.inject(constantConcurrentUsers(1).during(2.minutes))
.throttle(reachRps(30).in(30.seconds),holdFor(1.minute))
).protocols(httpProtocol)
}Tenemos que extender de Simulation. Posteriormente, obtenemos la base de nuestra URL, que en este ejemplo será http://localhost:8080, tras ello, definimos nuestro escenario utilizando las tres request que hemos mencionado arriba y, finalmente, definimos cómo queremos que sea nuestra prueba.
Esta prueba tiene una duración de 2 minutos utilizando sólo un único usuario concurrente y con una limitación de 30 peticiones por segundo mantenido durante 1 minuto.
Bundle
Ahora, vamos a hablar de la otra posibilidad a la hora de usar Gatling, que es utilizar la opción standalone o, también, ejecutar un bundle.
Para ejecutar un bundle tenemos que descargar un ZIP desde la página oficial de Gatling. Una vez descargado, tenemos que ejecutar el fichero gatling.sh. Tras ello, tenemos que elegir entre diferentes simulaciones que vienen disponibles por defecto:
Choose a simulation number:
[0] computerdatabase.BasicSimulation
[1] computerdatabase.advanced.AdvancedSimulationStep01
[2] computerdatabase.advanced.AdvancedSimulationStep02
[3] computerdatabase.advanced.AdvancedSimulationStep03
[4] computerdatabase.advanced.AdvancedSimulationStep04
[5] computerdatabase.advanced.AdvancedSimulationStep05Aquí, podríamos dejar la simulación anterior dentro del directorio user-files y la tendríamos disponible para ejecutar. Pero, en este caso, vamos a elegir la opción básica para no hacer la entrada muy larga:
Esto es útil para procesos automáticos de integración continua.
Una opción interesante, es utilizar la herramienta recorder.sh que viene disponible en el bundle. Si, por ejemplo, queremos ejecutar una prueba de carga basada en una navegación hecha con Chrome, basta con abrir inspeccionar elemento y en la pestaña Network, tras indicar que queremos preservar los logs (como se muestra en la imagen de abajo), podemos exportar la navegación como fichero HAL.

Este fichero HAL, que podemos exportar con el botón derecho (como se muestra más abajo), podemos cargarlo en la ventana gráfica que aparece al ejecutar el recorder.
Bastaría con elegir el modo HAR Converter, y cargar el fichero para reproducir dicha prueba:
Dashboard
Finalmente, y volviendo al primer ejemplo en el que teníamos un proyecto local, ejecutamos la prueba con el siguiente comando:
mvn gatling:testTenemos disponible en la carpeta target un fichero index.html que podemos abrir en nuestro navegador:
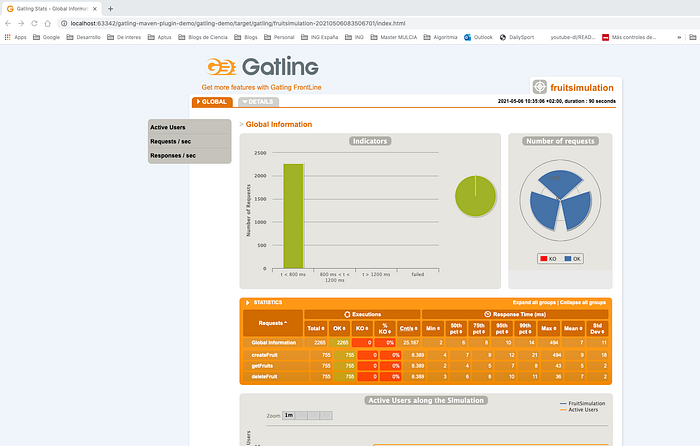
Tenemos disponible diferentes métricas, por ejemplo, la distribucción de los tiempos de respuesta:

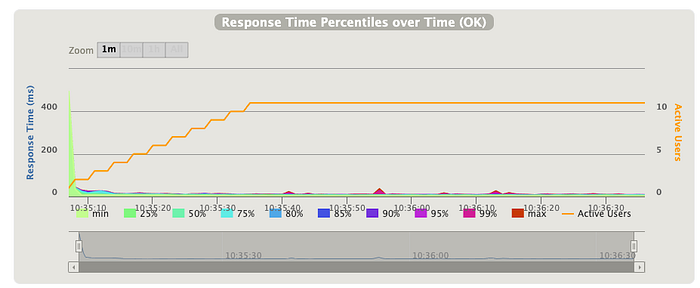
También, tenemos la posibilidad de ver la distribucción de percentiles a lo largo del tiempo en función de los usuarios activos:
O, para finalizar esta sección, el número de peticiones por segundo:

Conclusión
Estamos ante una herramienta muy potente y versátil para hacer pruebas de carga. Aquí, hemos pasado de puntillas intentando cubrir un poco todas las posibilidades a nivel general, pero hay mucho más.
Por ejemplo, se puede utilizar Docker para ejecutar las pruebas de carga de forma automática (ver esta imagen de Docker), se puede grabar una navegación desde el navegador, como ya hemos visto, y utilizar el código (Scala) generado para hacer una plantilla de pruebas a partir de datos dinámicos, etc.
